在当今高速发展的科学与工程领域,高性能计算(HPC)已成为推动创新、解决复杂问题的核心引擎。为了满足科研机构、高校及企业客户日益增长的大规模并行计算需求,亚马逊云科技(AWS)近期宣布了一项重要技术整合:将业界广泛使用的开源作业调度系统Slurm正式托管并深度集成至其Amazon ParallelCluster云超算平台中。这一举措标志着AWS在构建灵活、强大且易于管理的云端高性能计算解决方案方面迈出了关键一步,为计算机网络与科技领域的技术开发带来了新的范式。
一、 技术核心:Slurm与Amazon ParallelCluster的强强联合
Slurm(Simple Linux Utility for Resource Management)是一个开源、高可扩展的作业调度与集群管理工作系统,长期主导着全球顶尖超算中心和研究机构的计算资源管理。它以其卓越的可靠性、高效的资源管理能力和对复杂工作流的出色支持而闻名。
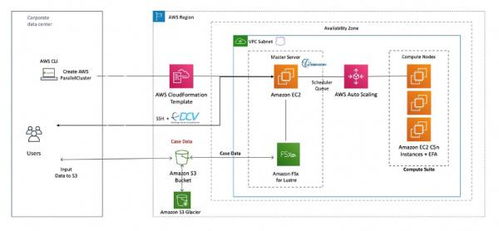
Amazon ParallelCluster则是AWS提供的一个开源集群管理工具,它允许用户在AWS云上快速部署和管理具备自动伸缩能力的高性能计算集群。用户通过简单的配置文件,即可启动一个集成了计算、存储、网络等资源的完整HPC环境。
此次技术开发的核心,是将Slurm作为一项完全托管的服务集成到ParallelCluster的架构中。这意味着AWS将负责Slurm控制节点的部署、配置、维护、监控和自动扩展,用户无需再像过去一样自行管理和运维调度器的基础设施层。这种托管模式将用户从繁琐的集群管理工作中解放出来,使其能够更专注于其核心的计算任务与应用开发。
二、 技术开发带来的关键优势
- 简化运维与提升效率:托管Slurm服务极大地简化了HPC集群的搭建与生命周期管理。用户无需成为Slurm专家即可快速启动一个生产就绪的集群。AWS自动处理补丁更新、安全加固和故障恢复,确保了调度器服务的高可用性与稳定性,显著降低了运维复杂性和成本。
- 无缝的弹性伸缩:深度集成使得Slurm能够与AWS的弹性计算服务(如Amazon EC2)以及ParallelCluster的伸缩策略无缝协同。集群可以根据作业队列的负载情况,自动动态地扩展或收缩计算节点规模。这种“按需付费”的弹性模式,使得用户能够以最优的成本应对计算峰值,避免了传统本地超算资源闲置或排队等待的困境。
- 强大的生态系统集成:托管Slurm能够原生地与AWS丰富的云服务结合。例如,计算节点可以轻松访问高性能的并行文件系统(如Amazon FSx for Lustre),作业数据可以存储在高容量的对象存储(Amazon S3)中,同时可以利用AWS CloudWatch进行深入的监控和日志记录。这为构建端到端的云上科研工作流和AI训练流水线提供了坚实基础。
- 保持开放性与兼容性:尽管是托管服务,AWS确保了与开源Slurm的API和命令行的高度兼容性。现有的基于Slurm的脚本、工作流和应用程序几乎可以无需修改即可迁移到云上运行,保护了用户的前期投资,降低了迁移门槛。
三、 对计算机网络与科技领域技术开发的影响
这一技术整合远不止于一项产品更新,它深刻影响着相关领域的技术开发模式:
- 推动HPC平民化与民主化:通过降低超算的使用门槛和管理负担,更多中小型研究团队、初创企业甚至个人开发者都能获得媲美顶级超算中心的计算能力,从而加速各领域的研发创新,从基因组学、流体动力学到金融建模和影视渲染。
- 催化混合云HPC架构成熟:托管Slurm为构建灵活的混合云HPC架构提供了理想的控制平面。企业可以轻松地将本地集群与AWS云端爆发能力相结合,在保障核心数据安全的利用云端无限资源应对突发性计算需求,这已成为现代HPC架构的重要趋势。
- 赋能AI与HPC的融合(HPDA/AI4Science):人工智能与高性能计算的结合是当前的前沿。一个由托管Slurm驱动的、弹性灵活的云超算平台,正是训练大规模AI模型、进行科学发现(如蛋白质结构预测、气候模拟)的理想基础设施。它能够为复杂的多步骤工作流(模拟-分析-机器学习)提供统一、高效的资源调度。
- 促进云原生HPC应用开发:开发者可以基于此稳定、托管的调度平台,更多地关注如何将应用程序优化以适应云环境的弹性特点,开发新一代云原生HPC应用,充分利用云服务的各种优势。
###
亚马逊云科技将托管Slurm引入Amazon ParallelCluster,是云计算技术与传统高性能计算领域一次深度而务实的融合。它不仅解决了用户在云上管理复杂作业调度系统的核心痛点,更通过云原生理念重塑了HPC资源的消费和管理方式。这项技术开发为全球的科研人员、工程师和开发者提供了一个更强大、更灵活、更经济的高性能计算平台,必将进一步激发其在科学研究、工程创新和商业洞察方面的潜力,持续推动计算机网络与科技领域向更高效、更智能的未来迈进。